
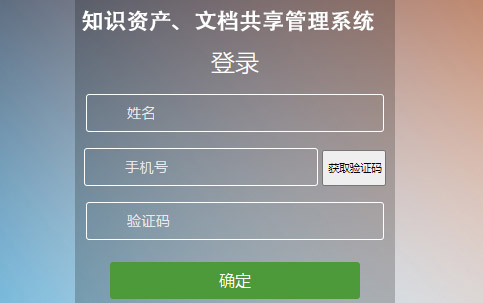
大家好,今天咱们来聊聊档案管理系统和科学代理之间的关系。其实啊,这玩意儿听着挺高大上的,但说白了就是用一些聪明的算法或者程序来帮我们自动处理数据。
比如说,你有一个档案系统,里面存了很多文件,每次用户要找东西的时候,系统得从一堆数据里快速找到对应的记录。这时候,如果有个“代理”程序在后台跑着,就能大大提升效率。这个代理可以是负责缓存、过滤或者权限控制的模块。
那么,怎么实现一个简单的代理呢?我们可以用Python写个例子。比如,定义一个档案类,然后创建一个代理类来包装它。这样,每次访问档案的时候,代理就会先做点检查或者处理。
下面是代码示例:
class Archive: def __init__(self): self.data = {} def get(self, key): return self.data.get(key, "未找到") def set(self, key, value): self.data[key] = value class ArchiveProxy: def __init__(self, archive): self.archive = archive def get(self, key): print("代理正在查找:", key) return self.archive.get(key) def set(self, key, value): print("代理正在存储:", key) self.archive.set(key, value) # 使用示例 archive = Archive() proxy = ArchiveProxy(archive) proxy.set("test", "这是测试数据") print(proxy.get("test"))
这个代理类可以在不改变原始档案类的情况下,增加额外的功能,比如日志记录、权限验证等。这就是科学代理的魅力所在。
所以,在实际开发中,合理使用代理机制,不仅能提高系统的可维护性,还能让档案管理系统变得更智能、更高效。
本站知识库部分内容及素材来源于互联网,如有侵权,联系必删!